
Accountability to Affected Population AAP
Published on: 2019-08-01نُشِرَ بتاريخ: 2019-08-01
Guide type: Introductory guide
Publish date: August 2019
Language: Arabic
Worked on this guide:
Ghaith Albahr
Bassel Faraj
Ghais Hmedan

Capacity Assessment Of Monitoring And Evaluation Departments In Syrian Organization
Published on: 2022-03-15نُشِرَ بتاريخ: 2022-03-15
Monitoring and Evaluation Department is considered one of the most important departments in NGOs, as it has an essential role in all phases of the project, starting from the planning of activities through assessing the needs of the targeted beneficiaries of the organization’s activities, and during the implementation phase and field follow-up, and even after the project ends through the process of final evaluation of the project and its impact assessment, and concluding lessons learned that can contribute to designing and developing future projects that the organization intends to implement, in addition to the role of the department in raising the degree of donors’ confidence in the organization.
Given the importance of the Work of MEAL Departments in NGOs, we conducted this study, which aims to identify the situation of the work of the M&E departments in Syrian organizations operating in Turkey, the extent to which these departments are organized, the existence of policies and SOP’s guides, its effectiveness within the organization and their relationship with the rest of the organization’s departments, in addition to identifying the expertise and competencies that workers of these departments possess and their most important training needs. The study included 20 Syrian organizations located in both Gaziantep and Istanbul.
The study showed that the Work of MEAL Departments in the majority of Syrian NGOs is limited to monitoring and evaluation only, without having a role in the accountability or learning process, and employees of these departments suffer a lack of expertise, especially expertise related to reports reporting, quality standards for questionnaires, sampling methodologies and PSEA, also, the vast majority of organizations lack policies and SOPs guides, in addition to the weak relationship and coordination between the M&E departments and the programs departments in about half of the organizations.
The study was conducted during October and November 2021.

Comparing SPSS vs Excel
Published on: 2022-04-25نُشِرَ بتاريخ: 2022-04-25
Data Analysis, Excel VS SPSS Statistics
An important question occurs to many of people interested in the field of data analysis or people who may need to use data analysis programs either for work or research; “What is the difference between Excel and SPSS? And when is each of them recommended?”.
In this article we provide a brief description of the advantages and disadvantages, this description is categorized according to the specialization or field of the required data analysis:
First: data analysis for academic research
We absolutely recommend using SPSS, as it offers very wide statistical analyses that has endless options. In this field, Excel cannot in any way provide what SPSS does.
For example, SPSS provides:
Parametric and non-parametric tests with wide options that include many tests required for researchers who are not specialized in statistics.
Regression and correlation analysis of its various types, linear and non-linear, with tests for them and analysis options that are widely related to them.
Time series analysis.
Questionnaire reliability tests.
Neural networks analysis.
Factorial analysis.
Survival analysis.
Statistical quality control analysis and charts.
Along with many other statistical analyses that serve academic fields.
Second: data analysis for non-academic research
It can be classified into several levels of data analysis:
Descriptive data analysis:
In general, the two programs are able to provide all the analyses required in descriptive statistical analysis, but Excel contains some minor flaws, such as that it does not arrange the answers according to their logical order, but rather in an alphabetical order, and it can’t provide calculations related to questions that include texts in addition to calculations related to their own order (Ordinal data) such as calculating the Likert Scale.
SPSS is characterized by providing tools for analyzing multi-select questions and with advanced options, which Excel does not provide, therefore, we need to use functions to get those analyses which options are limited with problems with the percentage that we get from it.
Disaggregation analysis:
It can be said that both programs are reliable in this aspect, except in the case of multiple and complex disaggregation/cross-tabulation with multi-select questions, in these cases, Excel becomes slower and less effective, while SPSS offers all options, no matter how complex they are, at the same speed required for descriptive statistical analysis and simple disaggregation. In addition to aforementioned, there are features such as filtering and data splitting features provided by SPSS, which accelerate data analysis to a very big scale, as it is possible to analyze the required data for 20 regions separately to be done at the same speed of analyzing data for one region, while in Excel, this means doing 20 times the work.
SPSS provides the features of descriptive analysis and data disaggregation much faster than we may think, as some analyses that take a week using Excel can be completed in just a few minutes using SPSS.
Third: Analyzing data of demographic indicators
When talking about demographic indicators, we find a challenge facing each of these two programs. In SPSS, we can perform numerous, complex and very fast arithmetic operations that outperform Excel, however, SPSS has some minor weaknesses that are important at the same time; among the most important matters that have been noticed in this regard is conducting multi-column conditional arithmetic operations, as SPSS provides multi-column arithmetic operations, but these operations do not contain multiple conditions, on the other hand, Excel provides this feature with a wide variety of conditional and effective functions.
Fourth: Data management and linking databases in the analysis
In this particular aspect, we find the clear distinction of Excel, as with the Power Query package, it offers features of data management, merging, and the possibility for aggregation and cleaning the data, in addition to the ability to link various databases without merging them, and analyzing them together with all types of analyses.
As for SPSS program, it does not include the feature of analyzing isolated databases without the need to merge them, on the other hand, it can solve a large part of this problem by merging databases, but this entails many challenges and great possibilities for error. When merging more than one database, there is usually a repetition of cases to match the other database, and this means that when we analyze the database that has been duplicated, we must perform operations that cancel this repetition in order to obtain correct analyses.
The features of data management and analyzing isolated databases together is considered as a great advantage of Excel, but in most cases it is not required, as it is only needed in complex and advanced projects.
On the other hand, SPSS program in the Data menu provides many features that can only be described as great, and the lines of this article are insufficient to talk about them, but they can be briefly described by saying that they gives data management some features that can outperform Excel in some aspects, such as the Unpivot or Restructure features that SPSS provides including features that are far more advanced and powerful than Excel.
Fifth: Weighting
One of the very important aspects of data analysis, especially with regard to demographic statistics, humanitarian needs analysis and advanced market research, is the Weighting feature, which helps to calculate the data after taking into account a weight that expresses, for example, the population of the governorate or the studied area, which gives it an amount of needs that is commensurate with its size.
This feature is not provided by Excel, if we wanted to calculate the weights manually using functions in it, this sometimes causes problems in the results, especially in the disaggregation analyses.
In SPSS, once you choose the option of Calculating Weights, it will be automatically applied to all calculations whatever they are, even on charts, and we can stop calculating weights with only one click.
This is a simple comparison between the two programs, we hope this comparison gives a preliminary perspective and help data analysis specialists and institutions that need to build the capacities of their team in this field to choose the most suitable program for them.
By:
Ghaith Albahr: CEO of INDICATORS

Field heroes 1 – Ethics of data collection
Published on: 2018-11-01نُشِرَ بتاريخ: 2018-11-01
Posted by admin Leave a comment
field-heroes-1-data-collection-ethics
Various institutions and organizations in their endeavors in seeking flawless implementation of their services conduct extensive studies before implementing their projects to have a better assessment for the needs of beneficiaries, and to identify ways in which these needs can be effectively and efficiently addressed.
Conducting these studies requires the existence of a field staff which conducts periodic visits to the targeted group to collect data and submit it to the analysts that turn this data into clear results that reflect the situation of the target group. It should be noted that the credibility of the concluded results depends on the accuracy of the data obtained in the field.
Proper collection of data and its success in achieving its objectives require the field researcher to be equipped with many skills, such as strong observation skills, the ability to use and employ the different senses, the ability to communicate with the participants to build upon the information they give, and having experience in the use of various data collection tools.
However, having expertise and skill alone is not sufficient for a field researcher to ensure the success of the data collection process and to acquire accurate information, which in turn leads to reaching objective results that reflect the condition of the target group. In order to reach that, field researcher must adhere to moral and ethical data collection principles which are defined as a set of standards and behavioral rules that govern and regulate the work of the field researcher while conducting data collection process.
In this guide we will mention the most important standards and ethics that the field researcher must adhere to
A series of guides for the data collectors to increase their skills in data collection for various research sectors.
Titles of the guides:
1. Data Collection ethics.
2. Individual and KI interviews.
3. Focus Group Discussion.
4. Field visit/Observation.

focus group discussions – Field heroes 3
Published on: 2018-11-03نُشِرَ بتاريخ: 2018-11-03
A series of guides for the data collectors to increase their skills in data collection for various research sectors.
Titles of the guides:
1. Data Collection ethics.
2. Individual and KI interviews.
3. Focus Group Discussion.
4. Field visit/Observation.
the third guide from the Field Heroes series is focus group discussions FGDs, which aims to develop the skills of enumerators and researchers in this field.
focus group discussions FGDs considers one of the hardest tools in data collection in terms of facilitating the session and ensuring the orientation of the discussions in a way that helps to obtain the data intended for the session, in addition to the sensitive role of the documented session and the ability to discuss and record useful information.
Worked on this guide:
Ghath Humaidan: manager of data collection teams
Khaled Brram: data analysis officer
Emad Al-Sari: market analysis specialist
Anas Jamous: field coordinator for data collection
Azzam Al-hadi: data quality officer
supervision Ghaith Al Bahr consultant in statistical Studies
Design: Omar Ghafrah- Faysal Al-Mashhadani
Report language: Arabic

Individual interviews – Field heroes 2
Published on: 2018-11-02نُشِرَ بتاريخ: 2018-11-02
Individual interviews
Individuals’ interviews are one of the most important tools in qualitative data collection and can be defined as an open talk between a field researcher and a person or group of people to discuss a set of questions related to a particular subject to obtain the data needed for the study, based on the knowledge of the participant or participants about the details of the subject under study.
Individuals’ interviews take between one hour to one hour and a half, and it can be done directly through a personal meeting between the field researcher and the participant, which is the most prevailing and appropriate form of conducting interviews, or by using modern means of communication such as Skype.
Advantages of individuals’ interviews:
Individuals’ interviews have many advantages, from which we can mention:
1-Individuals interviews are considered suitable for collecting data on important and sensitive issues such as those related to family matters or violence against children.
2-It is considered an opportunity for the field researcher to know the participant closely and help to obtain verbal answers and nonverbal indications that reinforce answers, such as expression changes on the participant’s face, his movements and emotional impressions, all that can be used in the data analyses process.
3-Individuals interviews help to motivate the participant to answer questions, ensure a correct interpretation of the questions and allow the participant to inquire about any ambiguity about the questions asked, and therefore, answers are more accurate and the percentage of errors is lower.
4- Individuals interviews are considered the best tools for data collection in illiterate communities, and in cases where the participant does not know how to read and write.
5-When doing individuals interviews, the field researcher is able to ask new questions related to the topic in question-based on the answers of the participant, and these questions help him get what he thinks is useful data.
6-Individuals’ interviews provide the field researcher with additional information about the subject in question and help him understand it well.
7-Individual interviews provide a good amount of data, where the percentage of replies and answers is higher than answers in written forms.
8-Individual interviews are considered the most appropriate way to collect data from important people, such as people with important positions in higher management.
9-Individual interviews allow the field researcher to return to the participant to ask more questions or inquire about some of the answers.
A series of guides for the data collectors to increase their skills in data collection for various research sectors.
Titles of the guides:
1. Data Collection ethics.
2. Individual and KI interviews.
3. Focus Group Discussion.
4. Field visit/Observation.
The second guide is the individual interviews, This guide includes six main themes:
The advantages of individual interviews, the disadvantages of individual interviews, the types of individual interviews, the preparation of individual interviews, conducting the individual interviews, the common mistakes that field researchers make when conducting interviews
Worked on this guide:
Ghath Humaidan: manager of data collection teams
Khaled Brram: data analysis officer
Emad Al-Sari: market analysis specialist
Anas Jamous: field coordinator for data collection
Azzam Al-hadi: data quality officer
supervision Ghaith Al Bahr consultant in statistical Studies
Design: Omar Ghafrah- Faysal Al-Mashhadani
Report language: Arabic

Issues of Asking Direct Questions
Published on: 2022-05-24نُشِرَ بتاريخ: 2022-05-24
Researchers and workers of all research fields (monitoring and evaluation, market research, opinion polls… etc.) usually work on identifying a set of research topics (usually called either research topics, key questions, or hypotheses…), then derive the questions that will be asked in the research tools from these topics. The problem I noticed that many researchers have, especially those working on developing #questionnaires / #research_tools, is that the phrasing of the questions uses almost the same words as the research topics. i.e., If we had a question about “the needs that would help increase the level of inclusion of people with disabilities in education”, the researcher asked people with disabilities “What are the needs that would help increase the level of your inclusion in education?”.
This method of phrasing results in many problems that would lead to not obtaining correct results or to a failure in answering the questions of the research, and this happens because:
1. The research topic may include terms that the participants are not familiar with, as academic terms are often used in research topics, therefore, other equivalent words that are used in real life must be used.
2. Most of the main research topics are complicated which cannot be answered by answering a single question, rather, they should be partitioned into sub-topics. Those sub-topics shall be phrased into questions (taking into consideration the appropriate amendment of the phrasing also), therefore, presenting the research topic directly and literally will cause confusion for the respondents, as they will be facing a broad and general question that is difficult for them to answer in this way.
3. In most cases, the participants do not have a level of knowledge that would help them answer the question in this form, this means that when studying the needs of people with disabilities that are required to increase their inclusion in education, it is better to ask the questions that related to the problems and difficulties they face that hinder their access to an appropriate education, with the necessity of emphasizing that asking about these problems and difficulties must be in a detailed way.
In summary, it can be said that the process of developing questionnaires appears to be easy for workers in this field, especially non-specialists, and anyone can work on the development of the questionnaires, but the experience, especially at the time of receiving data after all the efforts exerted for structuring the sample, and research methodology, shows that the data are useless, and this is due to the wrong design of the questionnaires.
Questionnaires can be expressed as the clearest example of the phrase “deceptively simple”, as anyone can develop a questionnaire, but the challenge comes with the obtained data. I recommend all workers in the field of research to improve their skills in #questionnaire_writing, and concentrate on the applied references, as most of the books only tackle theoretical aspects.
By:
Ghaith Albahr: CEO of INDICATORS

Issues of Dealing with Missing Values
Published on: 2022-05-20نُشِرَ بتاريخ: 2022-05-20
A lot of data analysis programs do not have the ability to distinguish between many values, namely:
· Missing Values
· Blanks
· Zero
This weakness of data analysis programs also extends to the failure of many data analysts to distinguish between these values, therefore, these values are not being distinguished or dealt with, and data are not being analyzed based on these differences.
Some may think that these differences are not very important, and they ignore them and leave dealing with them to data analysis programs, but in most cases, this gives catastrophic results that many people do not realize.
I will attempt to illustrate these differences through some examples:
1. If we want to analyze the average income of households in a country suffering from a crisis, it was noticed that a high percentage of respondents said that they have no income of any kind, and the percentage of these respondents is over 40% of the surveyed families. Data analysts dealt with these cases as missing values, the thing that gave results that are utterly different from the situation of society, as the socio-economic indicators in this case will show, for example, that only 10% of HHs are below the extreme poverty line, but the truth is that the percentage is more than 50%, because whoever does not have any income must be considered as his income is zero rather than a missing value, because the missing value is not included in the calculations, while the value zero is, and thus affects the percentages and the general average of income. In the opposite case, in the event of asking about the monthly salary, the salary of a person who does not have a job will be considered as a missing value rather than a zero, as he is unemployed and the salary is not calculated as a zero.
2. Many programs do not consider the blanks in the text questions as a missing value. For example, we find that the SPSS program does not consider the empty cell in the text questions as a missing value, but rather considers it a valid value, as in the Gender column, if it is a text question, the program will calculate the empty values, the thing that significantly affects results such as percentages, knowing that those who did not indicate their gender (male or female) should be considered a missing value.
3. In the SPSS, when trying to calculate a new data column from other columns, we find that some of the codes (formulas) can deal with the missing values effectively and some formulas cannot, for example when trying to calculate the total number of the family members out of the family members of each group, and we used the (sum) formula. We notice that SPSS gives the sum result even if there is a missing value in one of the categories, while calculating as a manual sum will give the sum result as a missing value when any of the cases with a missing value is encountered.
The cases in which there are issues in defining the missing values are unlimited, and I do not advise in any case to give the data analysis program nor the data analyst alone the freedom to guess and deal with those values, as the appropriate treatment and definition of the empty value must be determined, as we explained in the income case, the missing value must be considered as zero, while in the salary case, it must be considered a missing value, and in our third example, the empty cells of any category of family members must be considered zero, knowing that from the beginning, data collectors must be told that if a family does not have any member of a certain category, they must not leave a missing value, rather, they should fill it with a zero.
By:
Ghaith Albahr: CEO of INDICATORS

Local Community Perceptions Regarding Services and Decision Making Processes in NW Syria
Published on: 2022-06-03نُشِرَ بتاريخ: 2022-06-03
Large territories in northern Syria have been controlled by various opposition and other forces and non-state actors, after these territories were liberated from the control of the Syrian regime. While these entities govern the liberated areas, and are in charge of the affairs of the Syrians residing there by providing public services, maintain security, and resolve disputes, it is important to note that there is no single administrative and military entity which has a monopoly of control across the different parts of the region.
The present study was conducted to find out the reality of the liberated Syrian north, through identifying the entities responsible for governing each of these pieces of land, the status of public service provision and the level of citizen satisfaction, as well as understanding the state of affairs in terms of security, criminality, access to justice, and rule of law. Finally, the study aims to shed light to the decision-making mechanisms for important issues within the region, the extent to which citizens can participate in these mechanisms, and external influence on the governance and decision-making processes of the region.
The research has been designed and executed during the first half of 2021 in Idlib, Olive Branch and Euphrates Shield areas. It is based on field research involving survey of Syrians both from host communities and internally displaced persons (IDP’s) residing in the research area, and complemented with interviews with key informants (KIIs) from local government bodies or non-government organizations (NGOs).
The results of the study demonstrate a low level of knowledge of the residents of northern Syria of those responsible for governance and the provision of public services, mainly due to confusion between service providers and those responsible for managing the sector concerned. Another important result is in general, the residents of the region have low level of satisfaction for the services provided, which is being observed across all three regions.
With regard to the security situation, Idlib was the safest area according to the opinions of key informants and participants in the survey, where Hay’at Tahrir Al Sham was able to firmly control the security situation in the area and deal to a large extent with the security threats of bombings and kidnappings. Theft remains the main security concern in Idlib. In the areas of Euphrates Shield and Olive Branch, the level of safety was found to be very low, where both areas suffer from explosions targeting markets and residential areas as well as many cases of theft, kidnappings, killings and factional fighting. The people of Olive Branch area suffer especially from the seizing of their rights and property by military factions, and are being subject to arbitrarily arrest and kidnapping and have to pay funds get released.

observation – Field heroes 4
Published on: 2018-11-04نُشِرَ بتاريخ: 2018-11-04
Posted by admin Leave a comment
A series of guides for the data collectors to increase their skills in data collection for various research sectors.
Titles of the guides:
1. Data Collection ethics.
2. Individual and KI interviews.
3. Focus Group Discussion.
4. Field visit/Observation.
the fourth and final guide of the Field Heroes series, which provides an explanation of the appropriate mechanisms and procedures for collecting data through observation, which is usually done through a field visit to the project site.
The observation is one of the most important tools of data collection because it helps us to obtain information about the expressed needs, which are more credible than the felt needs of the people, and it’s also the main tool in the methodology of Design Thinking developed by Ideo to help create innovative products.
Worked on this guide:
Ghath Humaidan: manager of data collection teams
Khaled Brram: data analysis officer
Emad Al-Sari: market analysis specialist
Anas Jamous: field coordinator for data collection
Azzam Al-hadi: data quality officer
supervision Ghaith Al Bahr consultant in statistical Studies
Design: Omar Ghafrah- Faysal Al-Mashhadani
Report language: Arabic

Ordinal Questions , Challenges and Issues
Published on: 2022-05-23نُشِرَ بتاريخ: 2022-05-23
The ordinal questions, where the participant is asked to answer several options in order of priority contain many issues.
I will talk through my observation of many cases about these questions focusing on the negatives points:
1. The process of arranging options according to the most important and less important is a cumbersome and time-consuming process, so it is noted that most participants do not answer them seriously, and therefore the order obtained is inaccurate.
2. In the questions in which we choose the most three important answers in an orderly way, the order tends to follow the order of the same answers in the design of the questionnaire, meaning that the participants tend to choose the answers that are mentioned to them at the beginning as the most important.
3. A big problem with the analysis of the ordinal questions is due to the weakness of most statistical programs, and the lack of ready-made analytical methods for these questions, so the data analyst is forced to do manual calculations, which causes issues in the analysis.
4. A problem in the outputs of the analysis: -Calculating the order as weights will give a result that may exceed the real value, meaning that the numerical result that we will get does not express a real value, but rather expresses the weight and importance of this option compared to the other options and not the percentage of those who chose it.
-Many data analysts have difficulty dealing with these questions, so they tend to use inappropriate methods such as displaying the analysis of the first priority only, displaying the analysis of each priority separately, or analyzing the question as a usual multi-select question.
-An error in calculating weights, the weighting system in statistics is not arbitrary, that is, in cases, it is considered in the form of degrees 1, 2, 3, or in the form of probabilities or percentages of the original answers…etc.
-An error in defining the weights of the answers, as the first priority should take the number 3 and the third should take the number 1, knowing that the logical order is the opposite, but as a final value it must give a higher number to the first priority, and this is usually the mistake that some data analysts made.
5. Issues with the report writers where some of them are confused about how to present and discuss the results in the report correctly.
6. Problems in the disaggregation of ordinal questions with other questions, as the question exists in several columns in the database, in addition to the need to take into account the weights, and to the disaggregation with one or more questions, which leads to many data analysts to make mistakes in analyzing these questions
By:
Ghaith Albahr: CEO of INDICATORS
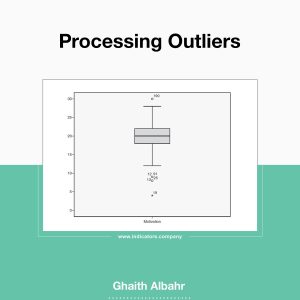
Outliers Processing
Published on: 2022-05-20نُشِرَ بتاريخ: 2022-05-20
Some data analysts do not grant any attention to outliers, and they may have first heard this term while reading this article. Outliers have a significant impact on many statistical indicators, and the methods of handling and processing them are related to many factors, some of which are simple, and some are more complex and related to the type of statistical indicator, as the data analyst must know the classification of the Smooth Parameters and the that’s not, and this indicates the degree to which it is affected by the outliers.
For example, the mean is considered one of the best indicators/coefficients of central tendency, but it is extremely affectable by outliers compared to the median, knowing that the median is not considered an accurate coefficient compared to the mean.
Within the following lines, I will try to tackle an important aspect related to the outliers, which is the simplest, it’s the methods of processing outliers:
Methods of processing outliers:
1. Revision of the source: we revise the source in order to check the value, if there is an entry mistake, it is corrected, such as writing the age for a study about children as 22 by mistake instead of 2, so, we simply discover that it is an entry mistake and correct it.
2. Logical processing of outliers: Mistakes of outliers can be discovered through logical processing, simply, when studying the labor force, for example, the data of a person who is 7 years old are deleted because he is not classified as a labor force.
3. Distinguishing between what to keep and what to delete: This process is considered very exhausting, as there are no precise criteria for accepting or rejecting outliers. In this regard, SPSS program offers a useful feature, which is classifying outliers into two types, Outliers (which are between the first/third quartile and one and a half of the inter-quartile range), and Extreme values (which are between one and a half to three times the inter-quartile range), in other words, data far from the center of the data and data extremely far from it, in this case this classification can be adopted by accepting outliers and deleting extreme values.
4. Replacing the outliers that have been deleted: The last and most sensitive step is the decision to deal with the deleted outliers, whether to keep them deleted (as missing values) or replace them, the challenge begins with the decision to replace them, as leaving them as missing values entails consequences and challenges, similarly, replacing them also entails consequences and challenges. The decision of replacing deleted outliers is followed by the appropriate methodology for replacement, as the process of replacing missing values is also complicated and has various methodologies and options, each of these methodologies will have an impact in a way on the results of data analysis (I will talk about replacing missing values in another post).
It is not simple to summarize the methodologies for dealing with outliers within these few lines, as deleting outliers puts us in front of other options; shall we leave it as a missing value or replace it with alternative values? Also, when we delete outliers and reanalyze the data, we will find that new outliers have appeared, these values were not considered outliers considering the database before it was modified (before deleting the outliers in the first stage), therefore, I recommend Data Analysts to study more about this topic, considering the extent of studying they need based on the volume and sensitivity of the data.
By:
Ghaith AlBahr (Mustafa Deniz): CEO of INDICATORS