905376567431
[email protected]
English
العربية
English
CONTACT US
English
العربية
English
Home
Market Research
Feasibility studies
Marketing research
Products development
Testing customers experience
Studying customers satisfaction
Interactive business follow-up platform
Socio Politics
Polls
Indicator’s development
Metrics development
Research partnership
Research statistical testing
Meal & TPM
Third-Party Monitoring (TPM)
Final Evaluation
Humanitarian needs assessment
Impact analysis
Market assessment
Development of MEAL policies & SOPs
Verification
Training
Agenda
Research studies
Guides
Interactive reports
Blog
About us
Search
OUR PROFILES
INDICATORS Profile
TPM
Market research
Trainings
Socio-politics
Free consultation
Request A Free Consultation
Your name
Your email
Subject
Your message (optional)
Contact Information
[email protected]
+90 537 656 74 31
İncilipınar Mah, Nail Bilen cd, Kantar İş Merkezi, kat 4, ofis 404, Şehitkamil, Gaziantep, Turkey
24/7 SUPPORT
Unlimited help desk
Menu
Home
Market Research
Feasibility studies
Marketing research
Products development
Testing customers experience
Studying customers satisfaction
Interactive business follow-up platform
Socio Politics
Polls
Indicator’s development
Metrics development
Research partnership
Research statistical testing
Meal & TPM
Third-Party Monitoring (TPM)
Final Evaluation
Humanitarian needs assessment
Impact analysis
Market assessment
Development of MEAL policies & SOPs
Verification
Training
Agenda
Research studies
Guides
Interactive reports
Blog
About us
Contact us
Syrians Online working
Published on:February 2, 2026
Comparing SPSS vs Excel
Published on:February 2, 2026
Ordinal Questions, Challenges and Issues
Published on:February 2, 2026
Rubbish data
Published on:February 2, 2026
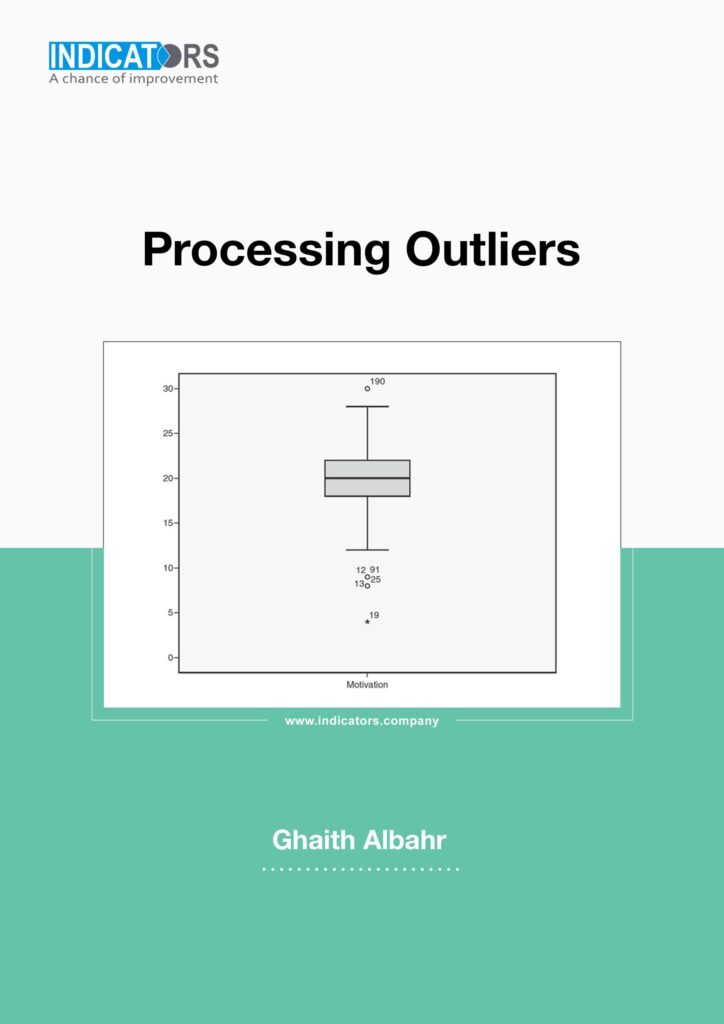
Outliers Processing
Published on:February 2, 2026
Issues of Dealing with Missing Values
Published on:February 2, 2026
Customer experience testing
Published on:February 2, 2026
Product Development
Published on:February 2, 2026
Unemployment In Saudi Arabia
Published on:February 2, 2026
PESTEL tool
Published on:February 2, 2026
Dell’s success story
Published on:February 2, 2026
Investment Studies Benefits And Most Important Tools
Published on:January 30, 2026
Issues of Asking Direct Questions
Published on:May 24, 2022
Home
Market Research
Feasibility studies
Marketing research
Products development
Testing customers experience
Studying customers satisfaction
Interactive business follow-up platform
Socio Politics
Polls
Indicator’s development
Metrics development
Research partnership
Research statistical testing
Meal & TPM
Third-Party Monitoring (TPM)
Final Evaluation
Humanitarian needs assessment
Impact analysis
Market assessment
Development of MEAL policies & SOPs
Verification
Training
Agenda
Research studies
Guides
Interactive reports
Blog
About us
Search
Start typing to see posts you are looking for.